Muestreo uniforme de árboles maximales. MCMC discreto
[latexpage]
En la vida hay muchas cosas que damos por sentado y es hasta que debemos realizarlas nosotros mismos que nos damos cuenta de que no siempre son tareas triviales. Obtener muestras de una distribución de probabilidad específica es una de ellas.
Generar una sucesión de números aleatoria y uniforme, que es probablemente el ejemplo más sencillo que se nos puede ocurrir, es de hecho el parteaguas de toda una área de investigación.
Los generadores pseudoaleatorios de números (GPAN) tienen una gran cantidad de aplicaciones y juegan un papel central en criptografía. El prefijo pseudo es porque las sucesiones de números que estos algoritmos arrojan quedan completamente determinadas por un conjunto de valores iniciales. Tal vez en otra entrada podamos entrar en la discusión filosófica sobre la existencia de la «aleatoriedad verdadera».
Ya existe mucha información sobre los GPAN y no es mi intención contribuir más al respecto. Los daremos por sentado por un momento y pensemos en muestras sobre un conjunto más interesante.
Supongamos que tenemos una gráfica conexa no dirigida con $n$ vértices, y queremos obtener un árbol maximal de $G$ tomado uniformemente entre todos los posibles.

Árbol maximal de una gráfica aleatoria ER obtenido uniformemente entre todos los posibles.
Uno de los primeros algoritmos publicados para este problema fue propuesto por Guénoche[1. A. Guénoche, “Random Spanning Tree”. Journal of Algorithms, 1983.] y tiene un tiempo de ejecución de $O(n^{5})$. Consiste en etiquetar las aristas en la gráfica de 1 a m, induciendo así un orden lexicográfico en el conjunto de los árboles, cualquier árbol puede ser encontrado calculando a lo más m determinantes.
Mejoras determinísticas de este algoritmo lograron reducir el número de determinantes a calcular [2. C. J. Colbourn, B.M. Debronim, and W.J Myrvold, «Estimating the coefficients of the reliability polynomial». Journal of Algorithms, 1996] [3. C. J. Colbourn, R.P.J Day and L. D. Nel, «Unranking and ranking spanning trees of a graph». Journal of Algorithms, 1989] [4. C. J. Colbourn, W.J Myrvold and E. Neufeld, «Two algorithms for unraking arborescences». Journal of Algorithms, 1996]. Con los nuevos y más complicados algoritmos se logró acortar el tiempo de ejecución a $O(n^{3})$ o $O(L(n))$, donde $L(n)$ es el tiempo para multiplicar matrices de $n\times n$.
Existe una alternativa probabilística de estos algoritmos. El algoritmo generate consiste en usar simulaciones de una cadena de Markov (caminata aleatoria simple) sobre la gráfica. Tiene un tiempo esperado de ejecución de $O(n^{3})$ llegando a $O(n\cdot log(n))$ en algunos casos.
Algoritmo Generate
Considere una partícula moviéndose en $G$. En cada paso la partícula se mueve aleatoriamente del vértice en el que está a alguno de sus vecinos escogido uniformemente. En términos concretos el algoritmo es el siguiente:
- Seleccione un vértice arbitrario $s$ de $G$
- Simule una caminata aleatoria simple en una gráfica $G$ hasta que cada vértice es visitado.
- Para cada $i$ en $V-s$ coleccione la arista $(j,i)$ donde la primera entrada corresponde al vértice en dónde se encontraba la partícula antes de pasar por primera vez por $i$. Sea $T$ la colección de dichas aristas.
- Devuelva el conjunto $T$.
Note que $T$ es en efecto una árbol maximal. Por construcción no tiene ciclos y consta de $|V| – 1$ aristas; tiene una arista para cada vértice en $G$ excepto $s$.
La cadena de Markov tiene distribución estacionaria $\pi_{i}=d_{i}/\sum_{j\in V} d_{j}$ donde $d_{i}$ es el grado del vértice $i$. La digráfica ponderada asociada a esta cadena $G_M =(V,E’)$, es obtenida reemplazando cada arista $\{i,j\}\in A$ por dos aristas dirigidas; $(i,j)$ con peso $1/d_{i}$ y $(j,i)$ con peso $1/d_{j}$. La demostración de que el muestreo es uniforme se puede resumir en los siguientes tres resultados, cuyas demostraciones completas pueden ser encontradas en el artículo de A. Broder [5. A. Z. Broder, «Generating random spanning trees». Journal of Theoretical Probability, 1989].
Denotaremos por $\mathcal{T}_{i}(G_{M})$ a la familia de árboles maximales dirgidos de $G_{M}$ con raíz $i$, cuando no hacemos reparación sobre la raíz los denotaremos simplemente por $\mathcal{T}(G_{M})$
Definimos $F_{t}$, el árbol de proa (forward tree) a tiempo $t$, como sigue: Sea $I_{t}$ el conjunto de estados visitados hasta antes del tiempo $t+1$. Para cada $i\in I_{t}$, sea $p(i,t)$ la primera vez que el estado $i$ fue visitado. La raíz del árbol $F_{t}$ es $X_{0}$ y los aristas de $F_{t}$ son $\{(X_{p(i,t)},X_{p(i,t)-1}) | i\in I_{t}-X_{0}\}$, donde $(X_{t})_{t\in \N}$ corresponde a la cadena de Markov dada por la caminata aleatoria. En otras palabras $F_{t}$ está formado superponiendo las aristas que corresponden a la primera entrada a cada estado con orientación invertida.
Así $F_{t}$ es un árbol dirigido con raíz donde cada arista apunta desde las hojas a la raíz. Denotaremos por $C$ al tiempo de cubrimiento; la primera vez que todos los estados fueron visitados. Para $t\geq C$ el árbol $F_{t}$ es un árbol maximal dirigido y $F_{t}=F_{C}$. De esta manera la caminata aleatoria $\{X_{t}\}$ en los vértices de $G_{M}$ induce una cadena de Markov $\{F_{t}\}$ en el espacio de todos los árboles dirigidos de $G_{M}$, llamada la cadena de árboles de proa. En esta cadena los árboles no maximales son estados transitivos y cada árbol maximal es un estado absorbente. El siguiente teorema establece la distribución de $F_{C}$.
Implementación computacional
Usando la librería networkX en python podemos generar la siguiente animación. Aparecen distintos elementos de una muestra de árboles maximales obtenidos con el algoritmo Generate sobre una gráfica aleatoria Erdös-Renyi.
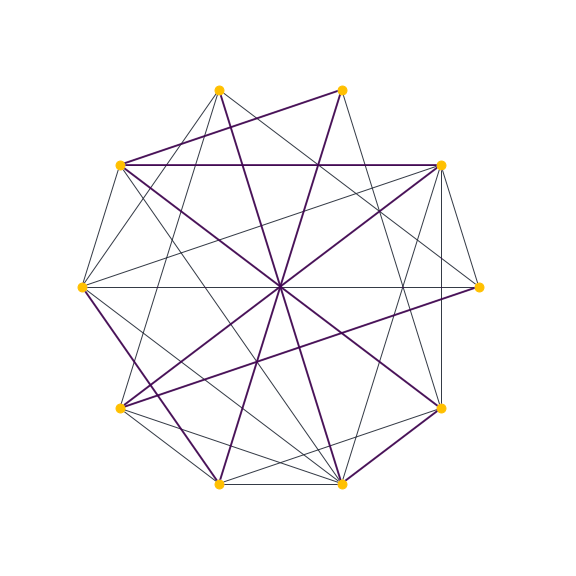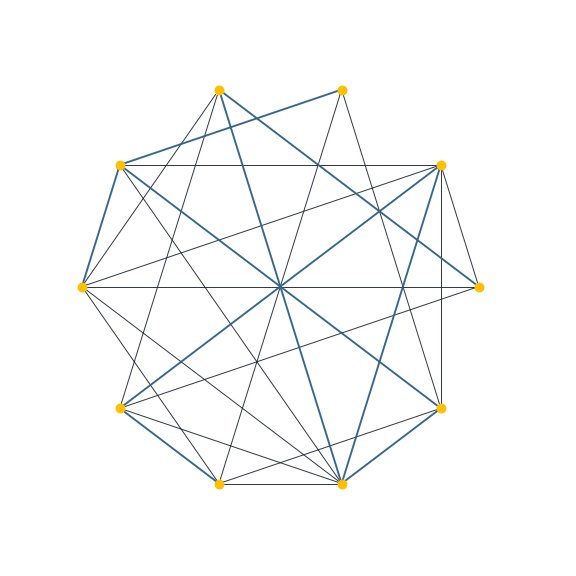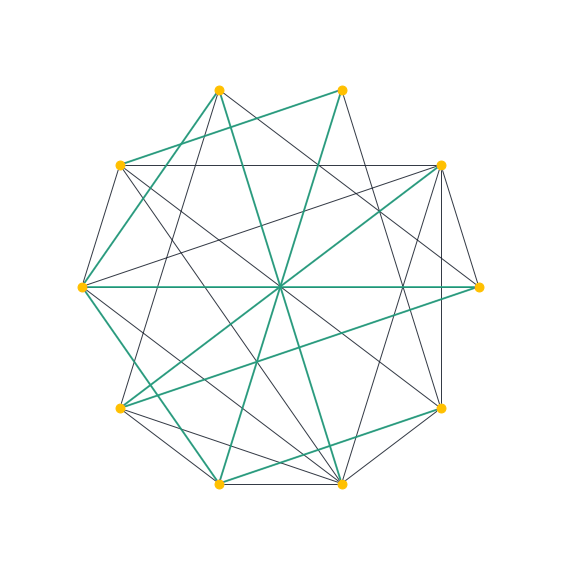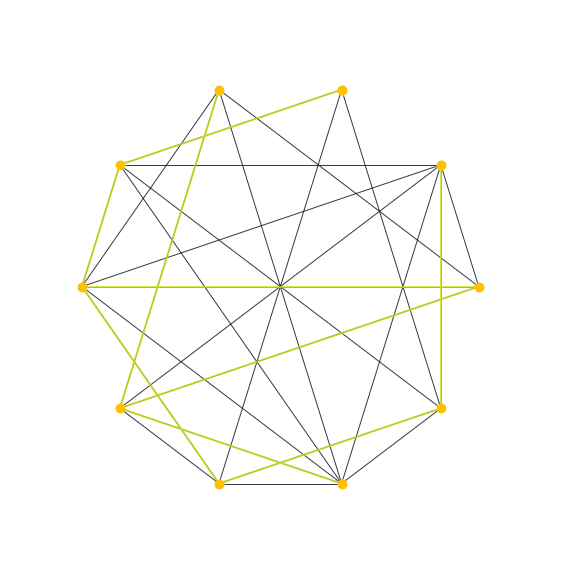
Tiempo de ejecución
El tiempo esperado de ejecución del algoritmo por árbol depende del tiempo esperado de cubrimiento, es decir $\E(C)$. Se sabe que para cada gráfica conexa $\E(C) = O(n^{3})$, sin embargo en otro artículo de A.Z Brorder [6. A.Z. Broder and A.R. Karlin, «Bounds on Cover Times». Journal of Theoretical Probability, 1989] se prueba que si la matriz de transición de una caminata aleatoria tiene el segundo eigenvalor más grande acotado lejos de 1, entonces el tiempo de cubrimiento esperado es solo $O(n\cdot log(n))$. Esta condición la satisfacen la mayoría de las gráficas en el modelo $\G(n,p)$ para cada $p > \frac{c\cdot log(n)}{n}$ [7. A.Z. Broder and E. Shamir, «On the second eigenvalue of random regular graphs». FOCS, 1987] en particular para $p=\frac{1}{2}$ y para casi todas la gráfica d-regulares [8. J. Friedman, J. Kahn, and E. Szemeredi, «On the second eigenvalue of random regular graphs». FOCS, 1989].
El uso de MCMC para obtención de muestras es poderoso. El caso discreto me parece muy amigable para un primer encuentro con herramientas de este tipo, aunque el caso continuo también es muy interesante y suele tener aplicaciones reales muy importantes (Estadística Bayesiana).
Si algún lector conoce o se le ocurre alguna aplicación para este algoritmo, me gustaría leerlo.